|
I am a fifth year Ph.D student in the Department of Automation at Tsinghua University, advised by Prof. Jiwen Lu . In 2021, I obtained my B.Eng. in the Department of Automation, Tsinghua University. I work on computer vision and robotics. My current research focus: Email / CV / Google Scholar / Github / LinkedIn |

|
|
*Equal contribution, †Project leader. |

|
Zhenyu Wu*, Xiuwei Xu*, Yukun Zhou, Yifan Li, Qiuping Deng, Xiaofeng Wang, Zheng Zhu, Bingyao Yu, Ziwei Wang, Jiwen Lu, Haibin Yan arXiv, 2026 [arXiv] [Code] [Project Page] We propose iMaC, an image-as-action control paradigm for embodied world models. iMaC converts robot actions into dense motion and contact images through URDF/FK rendering and RGB-D geometry, exposing spatial motion intention and robot-scene contact relations. These image controls enable contact-sensitive future prediction and closed-loop policy evaluation. |

|
Haoyu Wei, Xiuwei Xu†, Ziyang Cheng, Hang Yin, Angyuan Ma, Bingyao Yu, Jie Zhou, Jiwen Lu arXiv, 2026 [arXiv] [Code] [Project Page] We propose F2F-AP, a flow-to-future asynchronous policy for real-time dynamic manipulation. It predicts object flow to synthesize future observations and aligns visual features with future states, allowing policies to compensate for latency and interact with moving objects. |
|
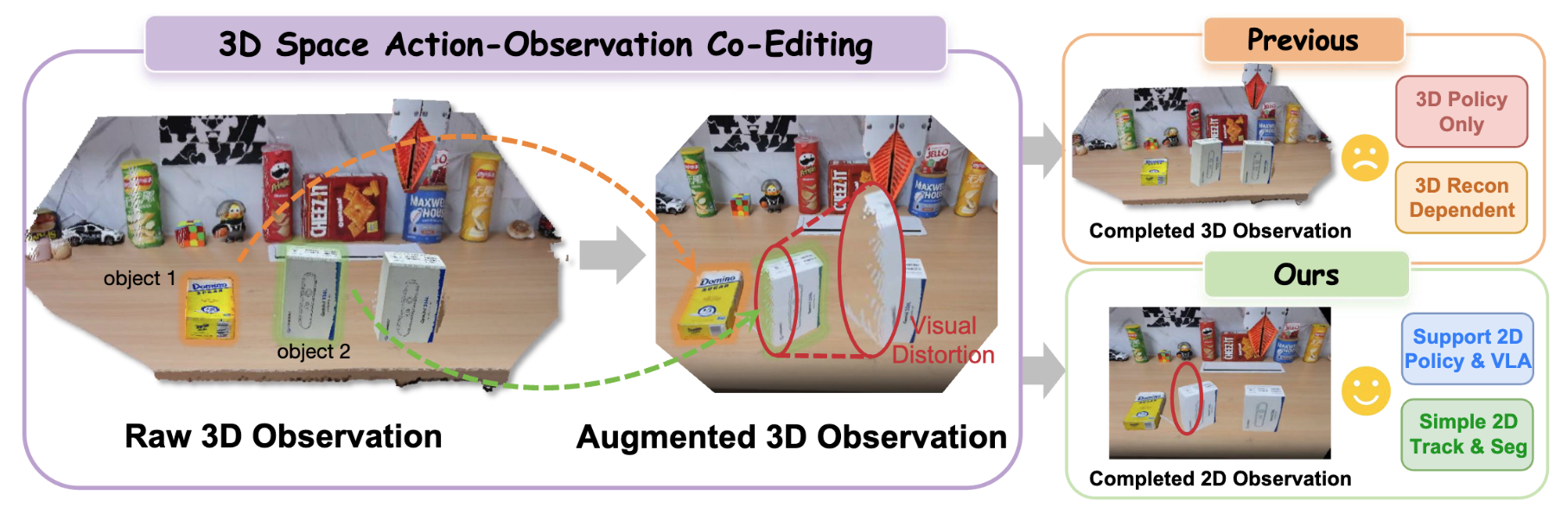
Xiuwei Xu*, Haowen Sun*, Angyuan Ma*, Yiwei Zhang, Zhenyu Wu, Xiaofeng Wang, Bingyao Yu, Zheng Zhu, Jie Zhou, Jiwen Lu arXiv, 2026 [arXiv] [Project Page] We propose R2RDreamer, a real-to-real demonstration augmentation framework for spatially generalized 2D manipulation policies. R2RDreamer edits incomplete object point clouds and end-effector trajectories in 3D, projects them into occlusion-aware image-space controls, and uses dense-control video completion to synthesize temporally coherent RGB-action demonstrations from limited real data. |
|
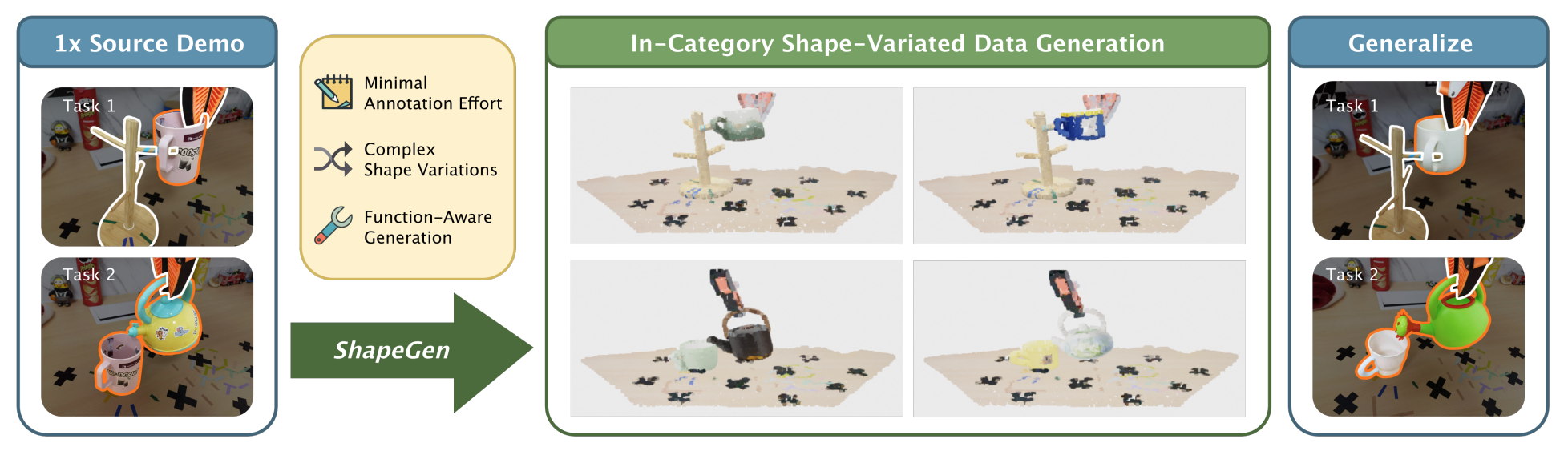
Yirui Wang, Xiuwei Xu, Angyuan Ma, Bingyao Yu, Jie Zhou, Jiwen Lu arXiv, 2026 [arXiv] [Project Page] We propose ShapeGen, a simulator-free 3D data generation method for category-level manipulation. ShapeGen builds function-aware shape libraries and generates shape-varied demonstrations with minimal human annotation, improving policy robustness to in-category geometric variations. |
|
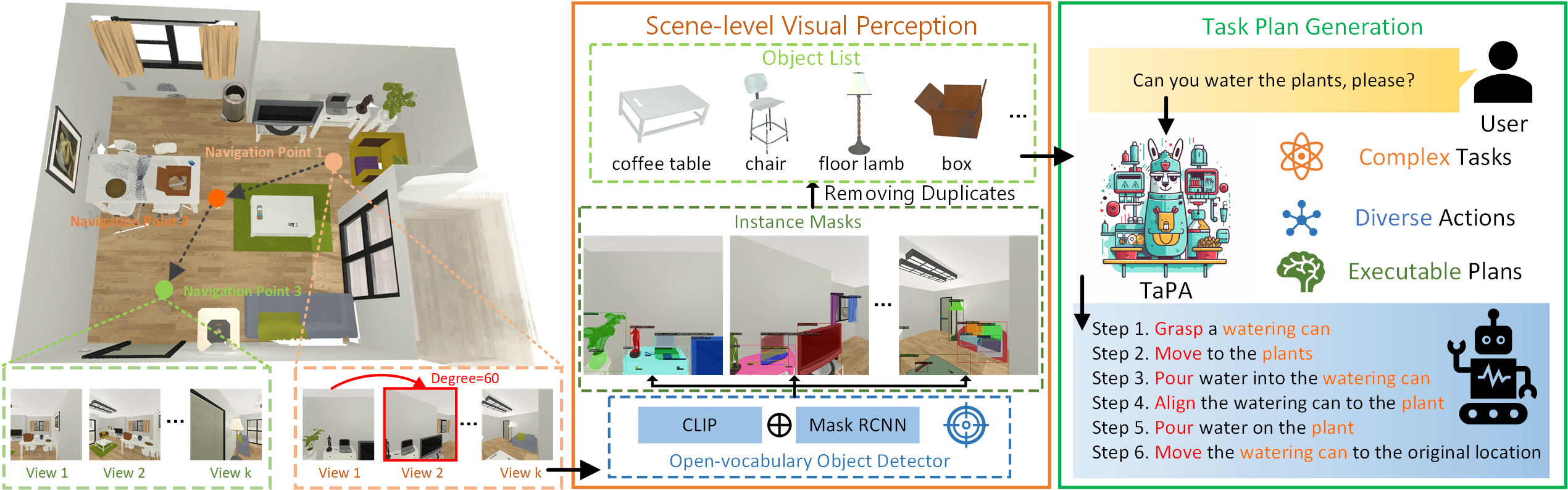
Zhenyu Wu, Ziwei Wang, Xiuwei Xu, Jiwen Lu, Haibin Yan arXiv, 2023 [arXiv] [Code] [Project Page] [Demo] We propose a TAsk Planing Agent (TaPA) in embodied tasks for grounded planning with physical scene constraint, where the agent generates executable plans according to the existed objects in the scene by aligning LLMs with the visual perception models. |
|
|

|
Xiuwei Xu*, Angyuan Ma*, Hankun Li, Bingyao Yu, Zheng Zhu, Jie Zhou, Jiwen Lu Robotics: Science and Systems (RSS), 2026 [arXiv] [Project Page] [Colab] We propose a real-to-real 3D data generation framework for robotic manipulation. R2RGen generates spatially diverse manipulation demonstrations for training real-world policies, requiring only one human demonstration without simulator setup. |
|
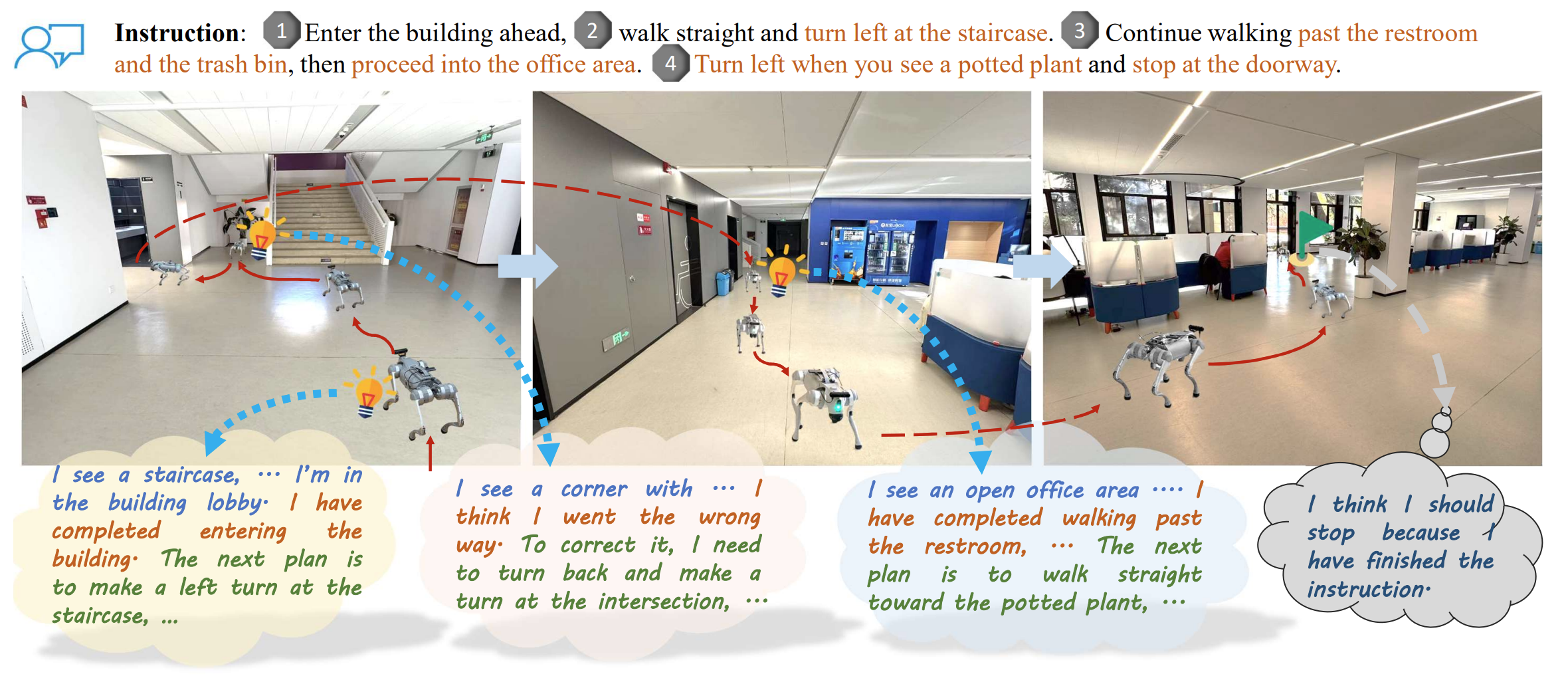
Wenxuan Guo, Xiuwei Xu†, Yichen Liu, Xiangyu Li, Hang Yin, Huangxing Chen, Wenzhao Zheng, Jianjiang Feng, Jie Zhou, Jiwen Lu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026 [arXiv] [Project Page] We propose AwareVLN, a self-aware reasoning framework for vision-language navigation. It triggers structured reasoning at key navigation nodes to understand scene context, task progress, and next-step plans, improving instruction following in simulation and real-world navigation. |

|
Zhenyu Wu*, Angyuan Ma*, Xiuwei Xu†, Hang Yin, Yinan Liang, Ziwei Wang, Jiwen Lu, Haibin Yan Conference on Robot Learning (CoRL), 2025 [arXiv] [Project Page] We propose a general framework for mobile manipulation, which can be divided into docking point selection and fixed-base manipulation. We model the docking point selection stage as an optimization process, to let the agent move and touch target keypoint under several constraints. |

|
Hang Yin*, Haoyu Wei*, Xiuwei Xu†, Wenxuan Guo, Jie Zhou, Jiwen Lu Conference on Robot Learning (CoRL), 2025 [arXiv] [Code] [Project Page] We propose a unified 3D graph representation for zero-shot vision-and-language navigation. By modeling instruction graph as constraints, we can solve the optimal navigation path accordingly. Wrong exploration can also be handled by graph-based backtracking. |

|
Wenxuan Guo*, Xiuwei Xu*, Hang Yin, Ziwei Wang, Jianjiang Feng, Jie Zhou, Jiwen Lu International Conference on Computer Vision (ICCV), 2025 [arXiv] [Code] [Project Page] We propose IGL-Nav, an incremental 3D Gaussian localization framework for image-goal navigation. It supports challenging scenarios where the camera for goal capturing and the agent's camera have very different intrinsics and poses, e.g., a cellphone and a RGB-D camera. |

|
Linqing Zhao*, Xiuwei Xu*, Yirui Wang, Hao Wang, Wenzhao Zheng, Yansong Tang, Haibin Yan, Jiwen Lu International Conference on Intelligent Robots and Systems (IROS), 2025 [arXiv] [Code] We propose an online RGB SLAM method that utilizes only monocular RGB input, eliminating the need for depth sensors or expensive iterative pose optimization. We propose to leverage 3DGS-based optimization to mitigate the error of depth estimator. |
|
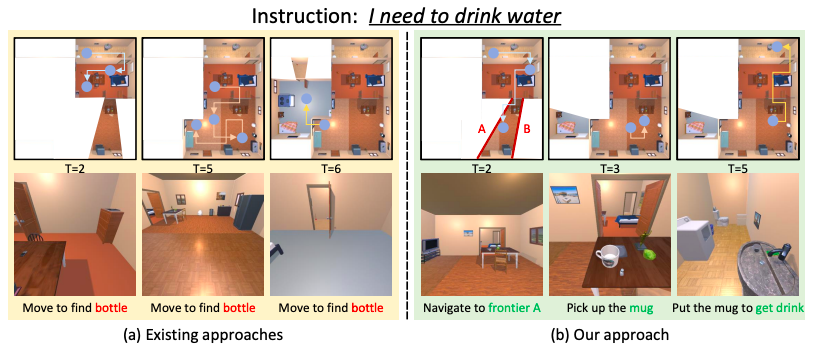
Zhenyu Wu, Ziwei Wang, Xiuwei Xu, Jiwen Lu, Haibin Yan International Conference on Intelligent Robots and Systems (IROS), 2025 [arXiv] [Code] [Project Page] Our embodied agent efficiently explores the unknown environment to generate feasible plans with existing objects to accomplish abstract instructions. which can complete complex human instructions such as making breakfast, tidying bedrooms and cleaning bathrooms in house-level scenes. |
|
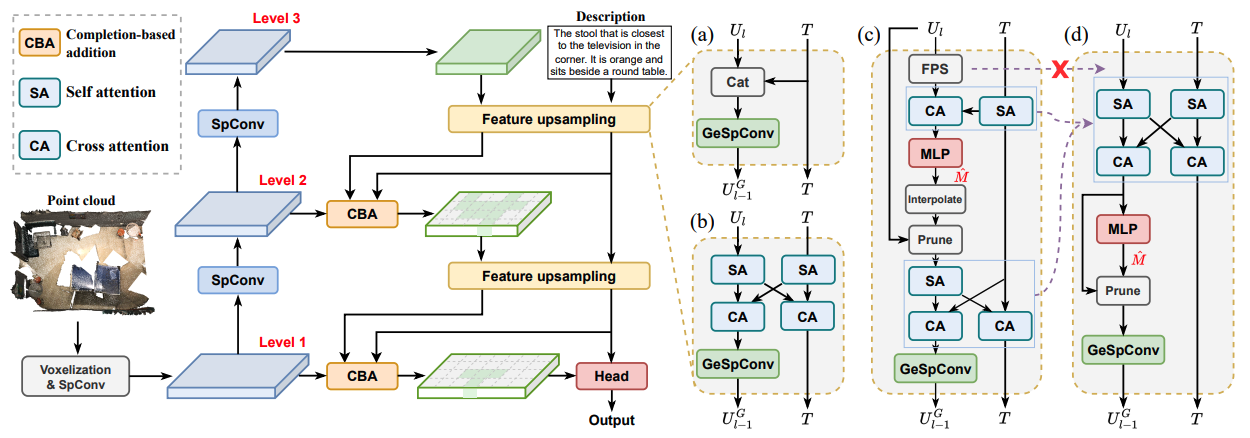
Wenxuan Guo*, Xiuwei Xu*, Ziwei Wang, Jianjiang Feng, Jie Zhou, Jiwen Lu Computer Vision and Pattern Recognition (CVPR), 2025 (Highlight, All Strong Accept) [arXiv] [Code] [中文解读] We propose TSP3D, an efficient multi-level convolution architecture for 3D visual grounding. TSP3D achieves superior performance compared to previous approaches in both accuracy and inference speed. |
|
Hang Yin*, Xiuwei Xu*†, Linqing Zhao, Ziwei Wang, Jie Zhou, Jiwen Lu Computer Vision and Pattern Recognition (CVPR), 2025 [arXiv] [Code] [Project Page] [中文解读] We propose UniGoal, a unified graph representation for zero-shot goal-oriented navigation. Based on online 3D scene graph prompting for LLM, our method can be directly applied to different kinds of scenes and goals without training. |

|
Zhenyu Wu, Yuheng Zhou, Xiuwei Xu, Ziwei Wang, Jiwen Lu, Haibin Yan Computer Vision and Pattern Recognition (CVPR), 2025 [arXiv] [Project Page] We propose an efficient policy adaptation framework named MoManipVLA to transfer pre-trained VLA models of fixed-base manipulation to mobile manipulation. We utilize pre-trained VLA models to generate waypoints of the end-effector with high generalization ability and devise motion planning objectives to maximize the physical feasibility of generated trajectory. |
|
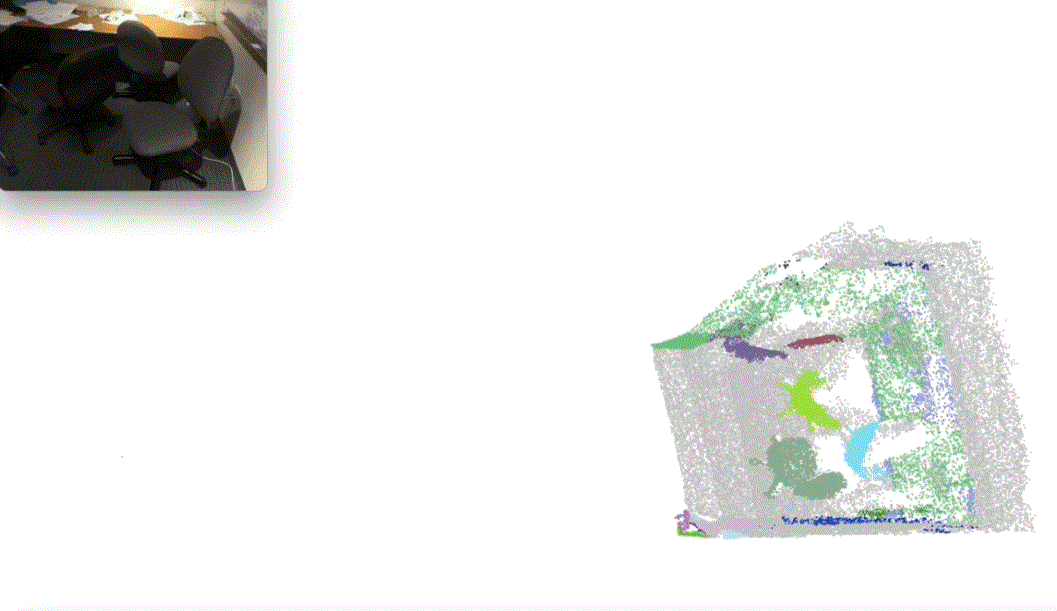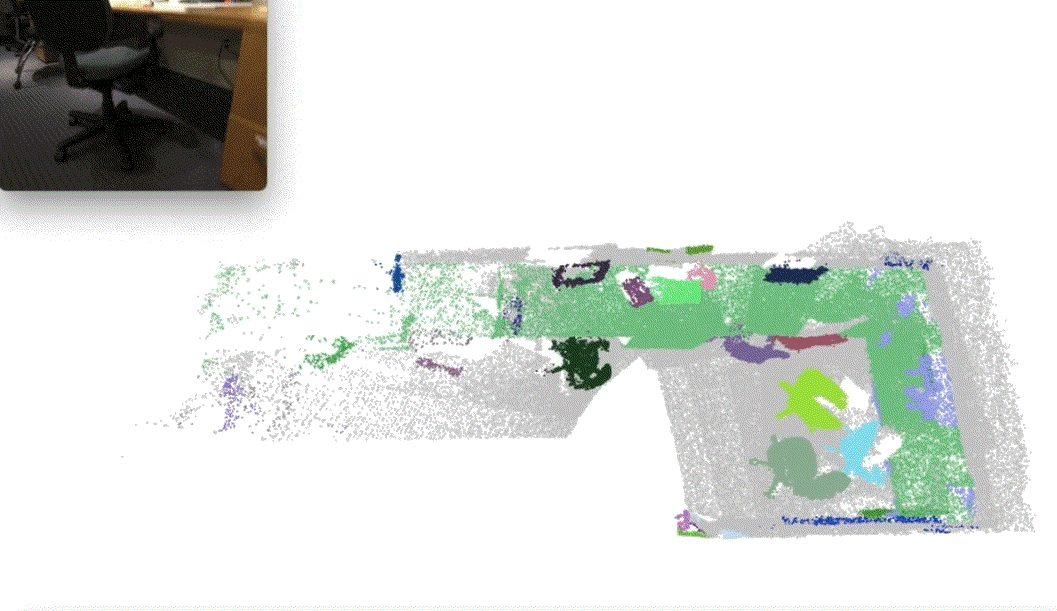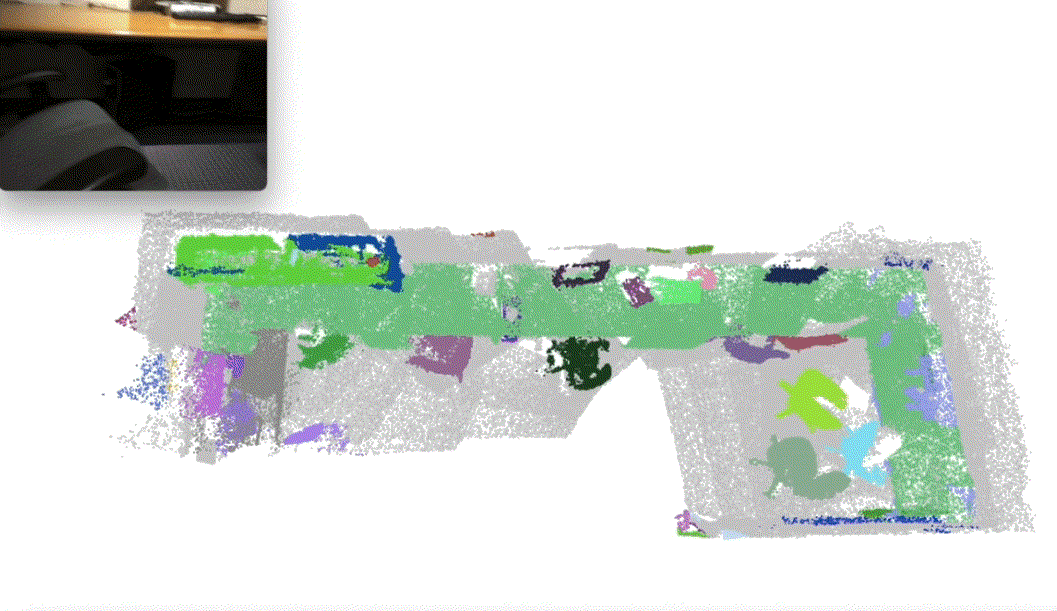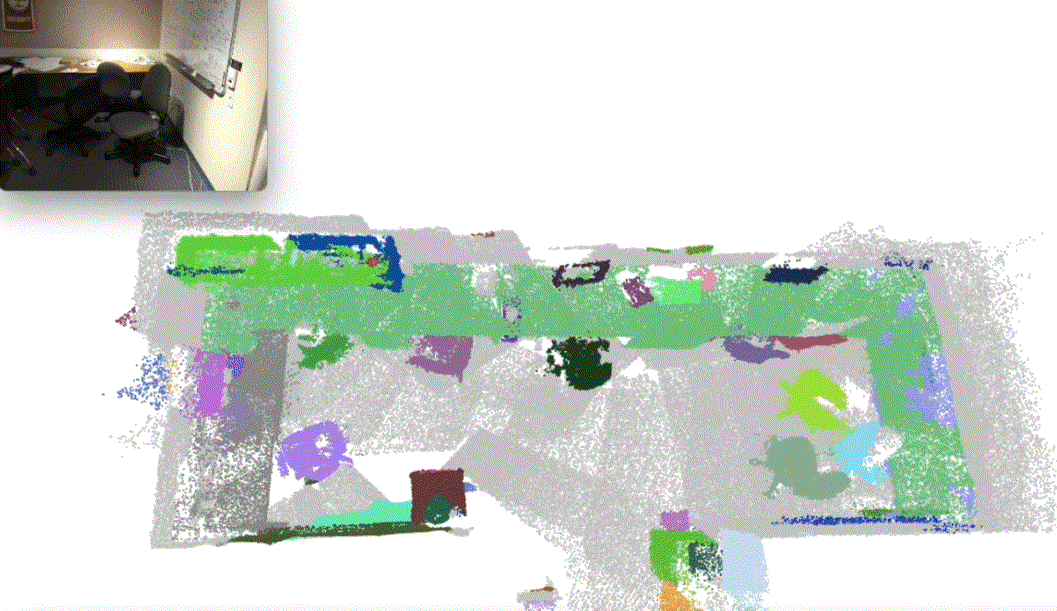
Xiuwei Xu, Huangxing Chen, Linqing Zhao, Ziwei Wang, Jie Zhou, Jiwen Lu International Conference on Learning Representations (ICLR), 2025 (Oral, Top 1.8% Submission) [arXiv] [Code] [Project Page] [中文解读] We presented ESAM, an efficient framework that leverages vision foundation models for online, real-time, fine-grained, generalized and open-vocabulary 3D instance segmentation. |
|
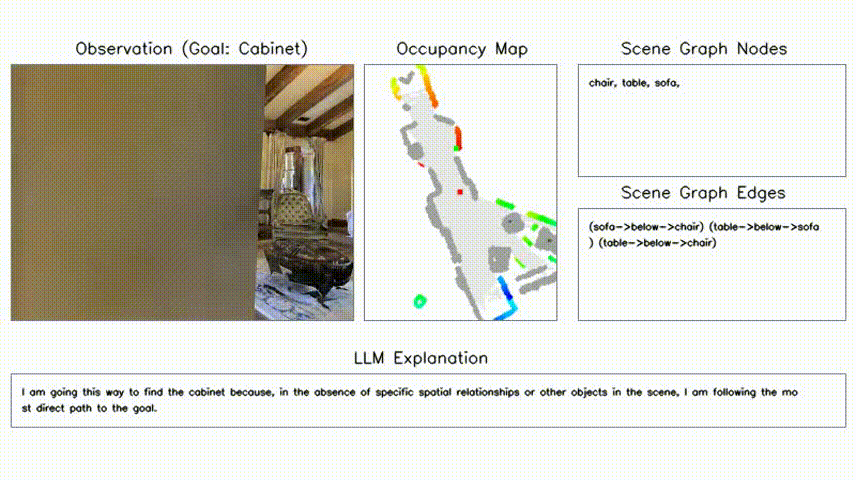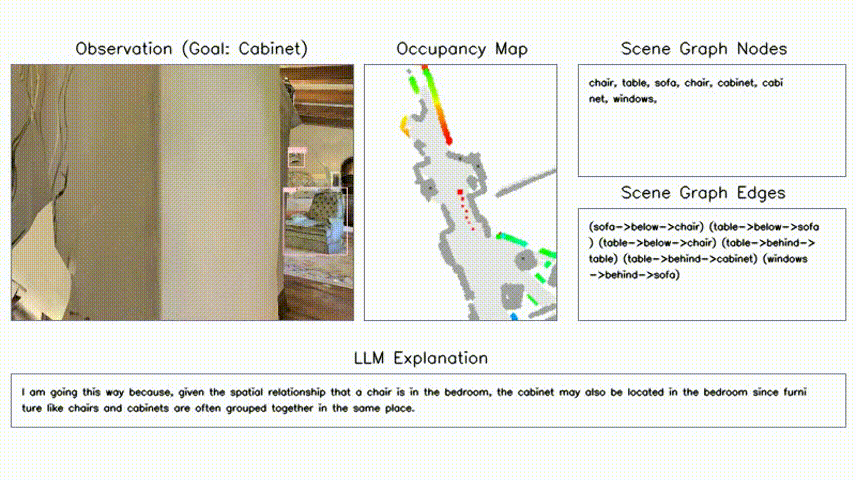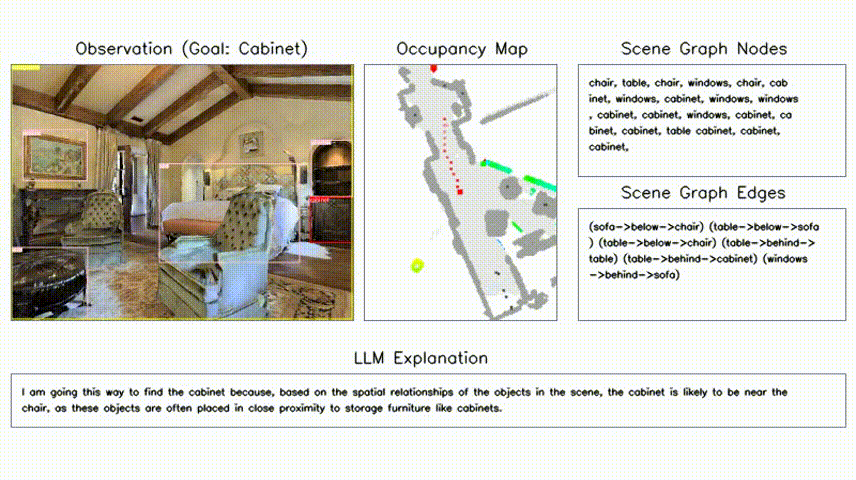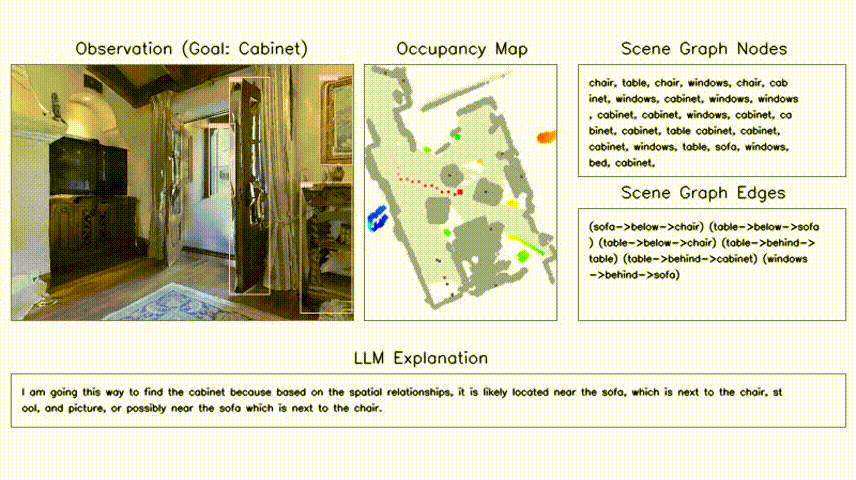
Hang Yin*, Xiuwei Xu*†, Zhenyu Wu, Jie Zhou, Jiwen Lu Neural Information Processing Systems (NeurIPS), 2024 [arXiv] [Code] [Project Page] [中文解读] We propose a training-free object-goal navigation framework by leveraging LLM and VFMs. We construct an online hierarchical 3D scene graph and prompt LLM to exploit structure information contained in subgraphs for zero-shot decision making. |
|
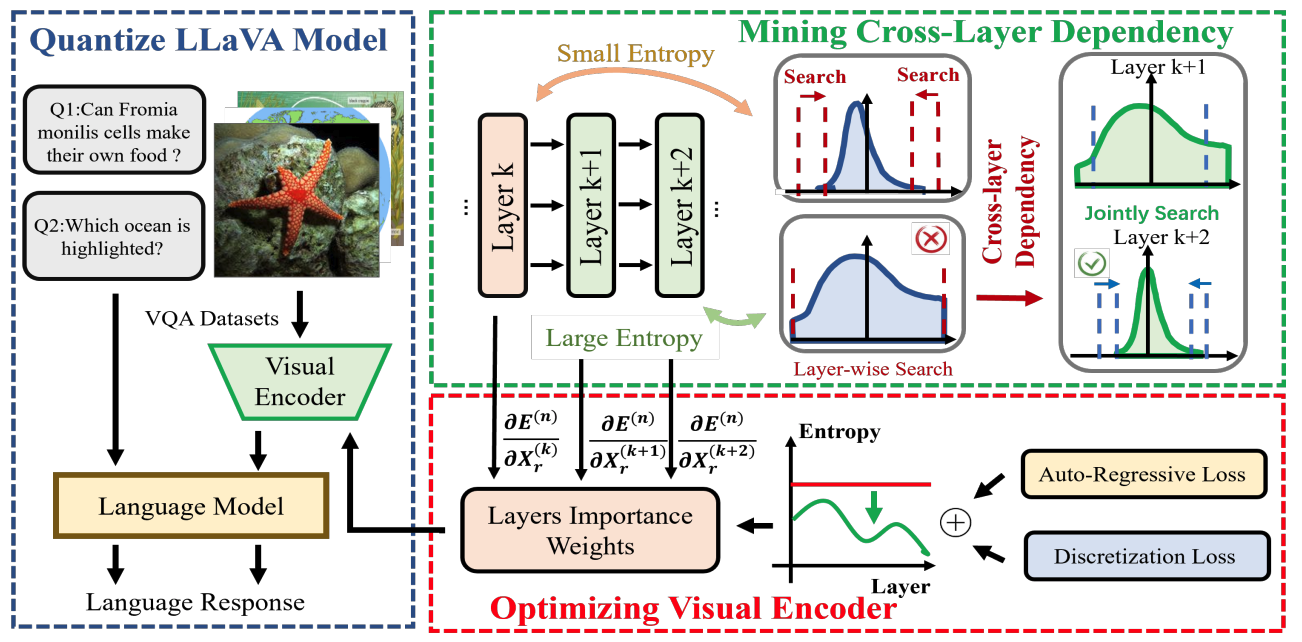
Changyuan Wang, Ziwei Wang, Xiuwei Xu, Yansong Tang, Jie Zhou, Jiwen Lu Neural Information Processing Systems (NeurIPS), 2024 [arXiv] [Code] We propose a post-training quantization framework of large vision-language models (LVLMs). Our method compresses the memory by 2.78x and increase the generate speed by 1.44x on 13B LLaVA model without performance degradation on diverse multi-modal reasoning tasks. |
|
Xiuwei Xu*, Zhihao Sun*, Ziwei Wang, Hongmin Liu, Jie Zhou, Jiwen Lu European Conference on Computer Vision (ECCV), 2024 [arXiv] [Code] [Project Page] [中文解读] We propose an effective and efficient 3D detector named DSPDet3D for detecting small objects. By scaling up the spatial resolution of feature maps and pruning uninformative scene representaions, DSPDet3D is able to capture detailed local geometric information while keeping low memory footprint and latency. |
|
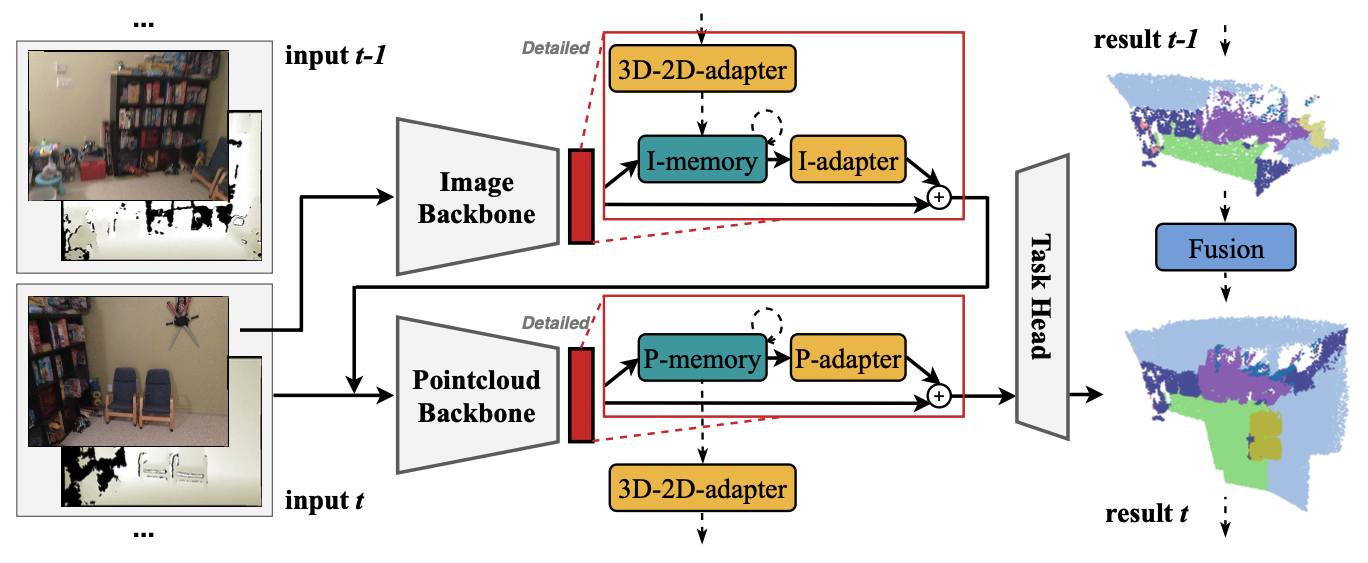
Xiuwei Xu*, Chong Xia*, Ziwei Wang, Linqing Zhao, Yueqi Duan, Jie Zhou, Jiwen Lu Computer Vision and Pattern Recognition (CVPR), 2024 [arXiv] [Code] [Project Page] [中文解读] We propose a model and task-agnostic plug-and-play module, which converts offline 3D scene perception models (receive reconstructed point clouds) to online perception models (receive streaming RGB-D videos). |
|
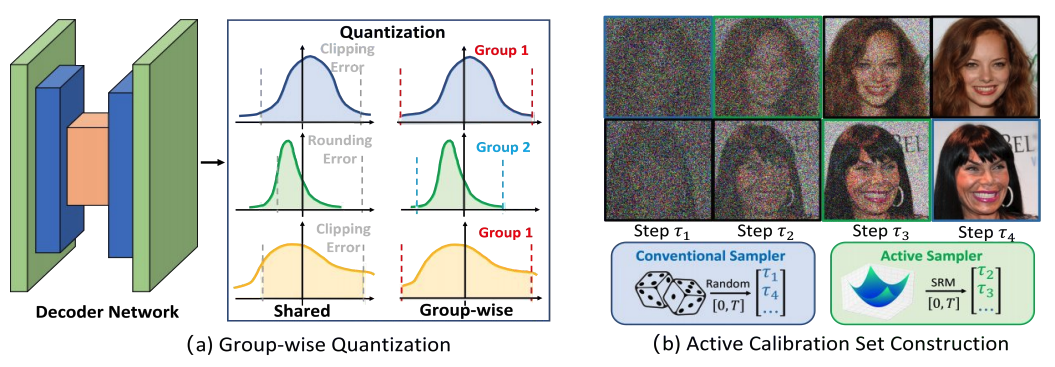
Changyuan Wang, Ziwei Wang, Xiuwei Xu, Yansong Tang, Jie Zhou, Jiwen Lu Computer Vision and Pattern Recognition (CVPR), 2024 (Highlight, Top 2.8% Submission) [arXiv] [Code] We propose a post-training quantization framework to compress diffusion models, which performs group-wise quantization to minimize rounding errors across time steps and selects generated contents in the optimal time steps for calibration. |
|
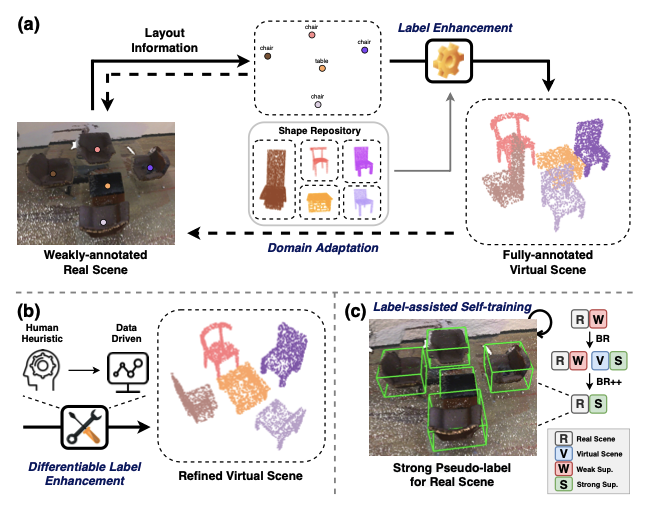
Xiuwei Xu, Ziwei Wang, Jie Zhou, Jiwen Lu IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI, IF: 23.6), 2023 [PDF] [Supp] [Code] We extend BR to BR++ by introducing differentiable label enhancement and label-assisted self-training. Our approach surpasses current weakly-supervised and semi-supervised methods by a large margin, and achieves comparable detection performance with some fully-supervised methods with less than 5% of the labeling labor. |
|
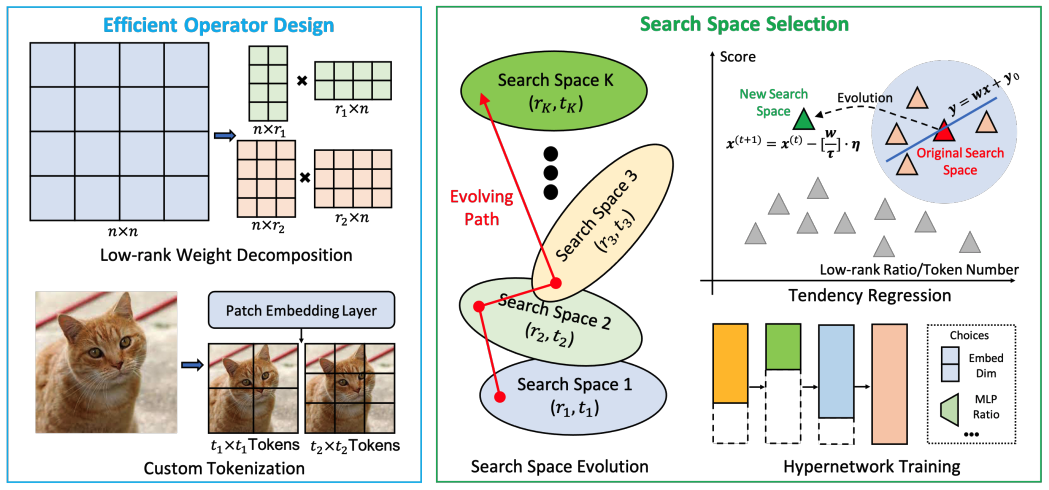
Yinan Liang, Ziwei Wang, Xiuwei Xu, Yansong Tang, Jie Zhou, Jiwen Lu Neural Information Processing Systems (NeurIPS), 2023 [arXiv] [Code] [中文解读] We propose a hardware-algorithm co-optimizations method called MCUFormer to deploy vision transformers on microcontrollers with extremely limited memory, where we jointly design transformer architecture and construct the inference operator library to fit the memory resource constraint. |
|
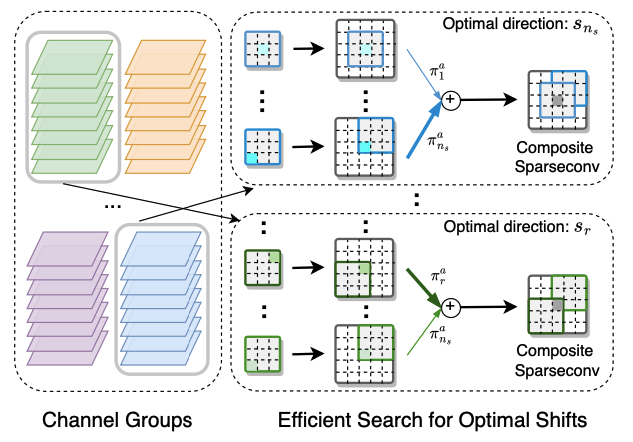
Xiuwei Xu, Ziwei Wang, Jie Zhou, Jiwen Lu Computer Vision and Pattern Recognition (CVPR), 2023 [arXiv] [Poster] We propose a binary sparse convolutional network called BSC-Net for efficient point cloud analysis. With the presented shifted sparse convolution operation and efficient search method, we reduce the quantization error for sparse convolution without additional computation overhead. |
|
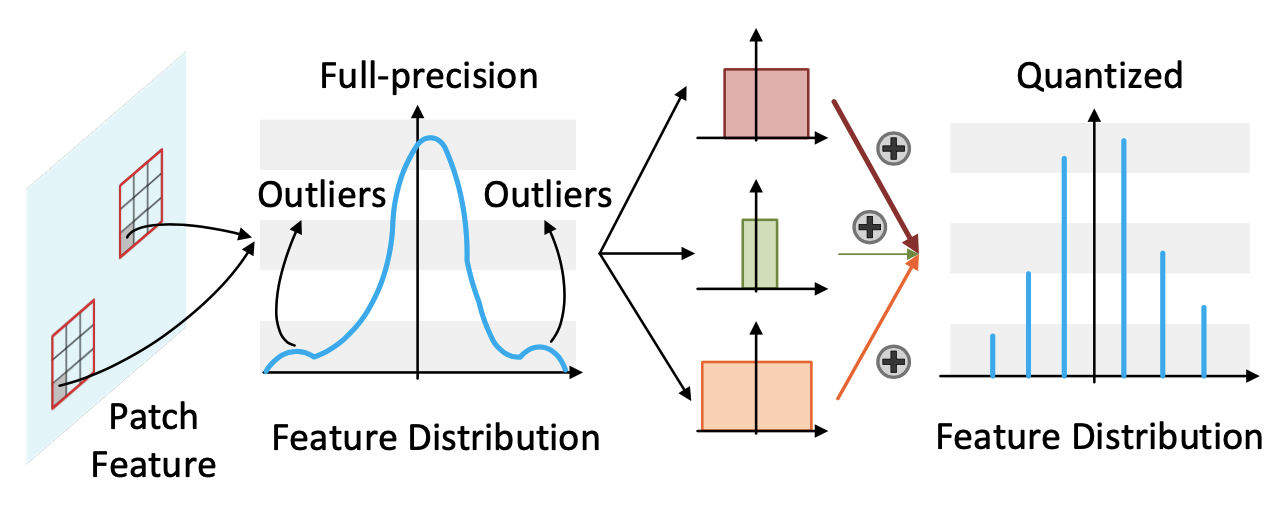
Ziwei Wang, Changyuan Wang, Xiuwei Xu, Jie Zhou, Jiwen Lu IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI, IF: 23.6), 2022 [PDF] [Supp] [Code] We propose the extremely low-precision vision transformers in 2-4 bits, where a self-attention rank consistency loss and a group-wise quantization strategy are presented for quantization error minimization. |
|
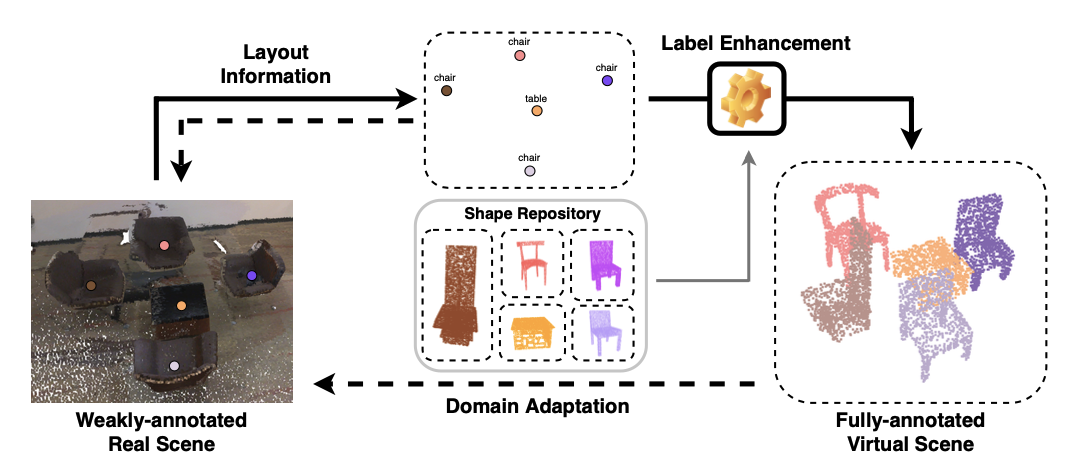
Xiuwei Xu, Yifan Wang, Yu Zheng, Yongming Rao, Jie Zhou, Jiwen Lu Computer Vision and Pattern Recognition (CVPR), 2022 [arXiv] [Code] [Poster] We propose a weakly-supervised approach for 3D object detection, which makes it possible to train a strong 3D detector with only annotations of object centers. We convert the weak annotations into virtual scenes with synthetic 3D shapes and apply domain adaptation to train a size-aware detector for real scenes. |
|
|