|
I am a fifth year Ph.D student in the Department of Automation at Tsinghua University, advised by Prof. Jiwen Lu . In 2021, I obtained my B.Eng. in the Department of Automation, Tsinghua University. I work on computer vision and robotics. My current research focuses on: Email / CV / Google Scholar / Github / LinkedIn |

|
|
|
|
*Equal contribution, †Project leader. |

|
Xiuwei Xu*, Angyuan Ma*, Hankun Li, Bingyao Yu, Zheng Zhu, Jie Zhou, Jiwen Lu arXiv, 2025 [arXiv] [Project Page] [Colab] We propose a real-to-real 3D data generation framework for robotic manipulation. R2RGen generates spatially diverse manipulation demonstrations for training real-world policies, requiring only one human demonstration without simulator setup. |
|
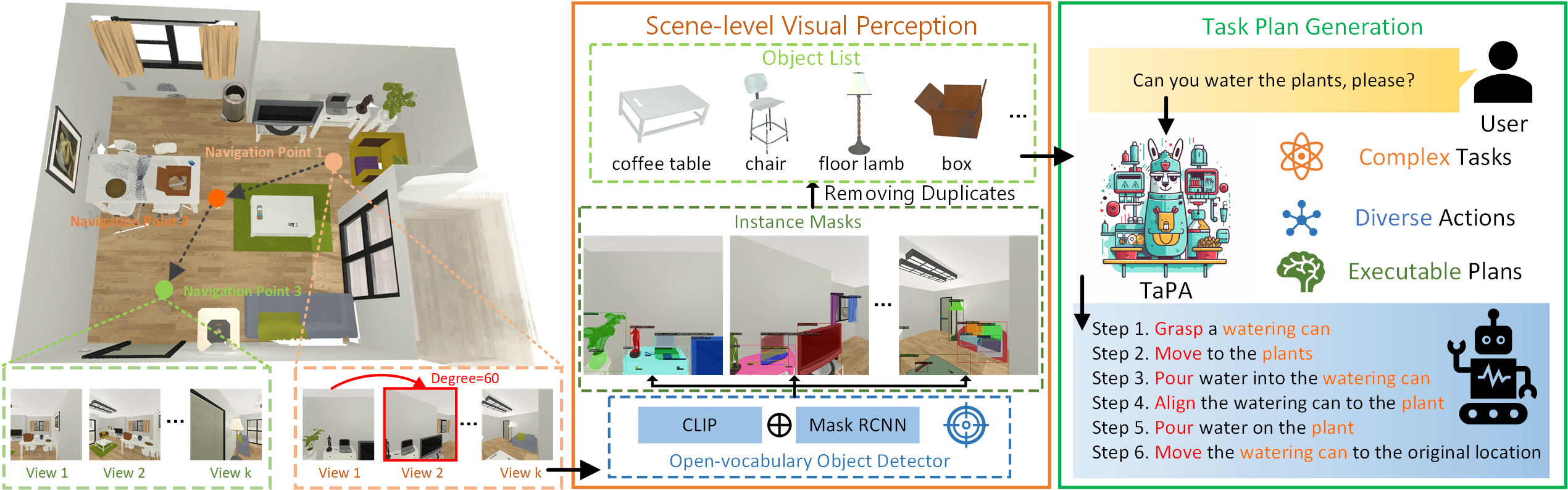
Zhenyu Wu, Ziwei Wang, Xiuwei Xu, Jiwen Lu, Haibin Yan arXiv, 2023 [arXiv] [Code] [Project Page] [Demo] We propose a TAsk Planing Agent (TaPA) in embodied tasks for grounded planning with physical scene constraint, where the agent generates executable plans according to the existed objects in the scene by aligning LLMs with the visual perception models. |
|
|

|
Zhenyu Wu*, Angyuan Ma*, Xiuwei Xu†, Hang Yin, Yinan Liang, Ziwei Wang, Jiwen Lu, Haibin Yan Conference on Robot Learning (CoRL), 2025 [arXiv] [Project Page] We propose a general framework for mobile manipulation, which can be divided into docking point selection and fixed-base manipulation. We model the docking point selection stage as an optimization process, to let the agent move and touch target keypoint under several constraints. |

|
Wenxuan Guo*, Xiuwei Xu*, Hang Yin, Ziwei Wang, Jianjiang Feng, Jie Zhou, Jiwen Lu International Conference on Computer Vision (ICCV), 2025 [arXiv] [Code] [Project Page] We propose IGL-Nav, an incremental 3D Gaussian localization framework for image-goal navigation. It supports challenging scenarios where the camera for goal capturing and the agent's camera have very different intrinsics and poses, e.g., a cellphone and a RGB-D camera. |
|
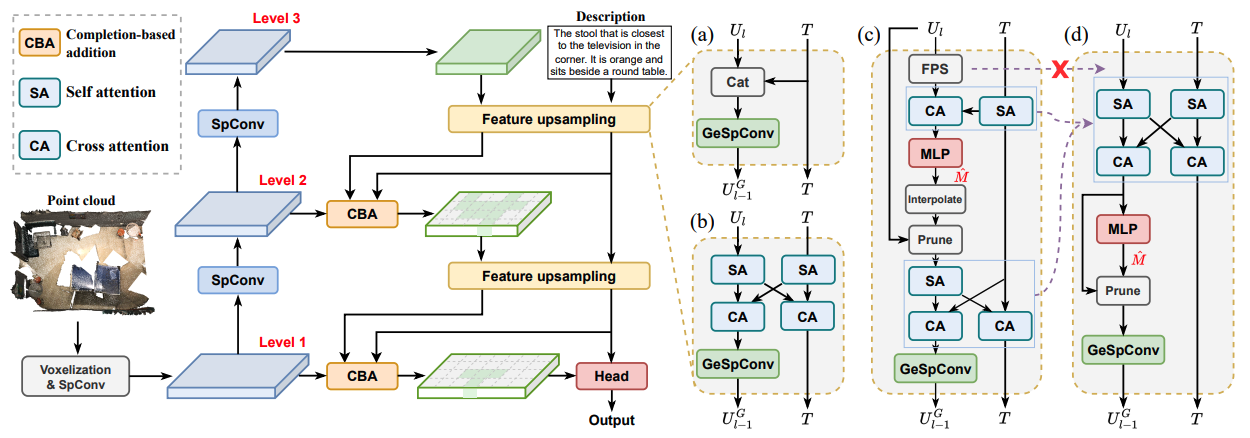
Wenxuan Guo*, Xiuwei Xu*, Ziwei Wang, Jianjiang Feng, Jie Zhou, Jiwen Lu Computer Vision and Pattern Recognition (CVPR), 2025 (Highlight, All Strong Accept) [arXiv] [Code] [中文解读] We propose TSP3D, an efficient multi-level convolution architecture for 3D visual grounding. TSP3D achieves superior performance compared to previous approaches in both accuracy and inference speed. |
|
Hang Yin*, Xiuwei Xu*†, Linqing Zhao, Ziwei Wang, Jie Zhou, Jiwen Lu Computer Vision and Pattern Recognition (CVPR), 2025 [arXiv] [Code] [Project Page] [中文解读] We propose UniGoal, a unified graph representation for zero-shot goal-oriented navigation. Based on online 3D scene graph prompting for LLM, our method can be directly applied to different kinds of scenes and goals without training. |
|
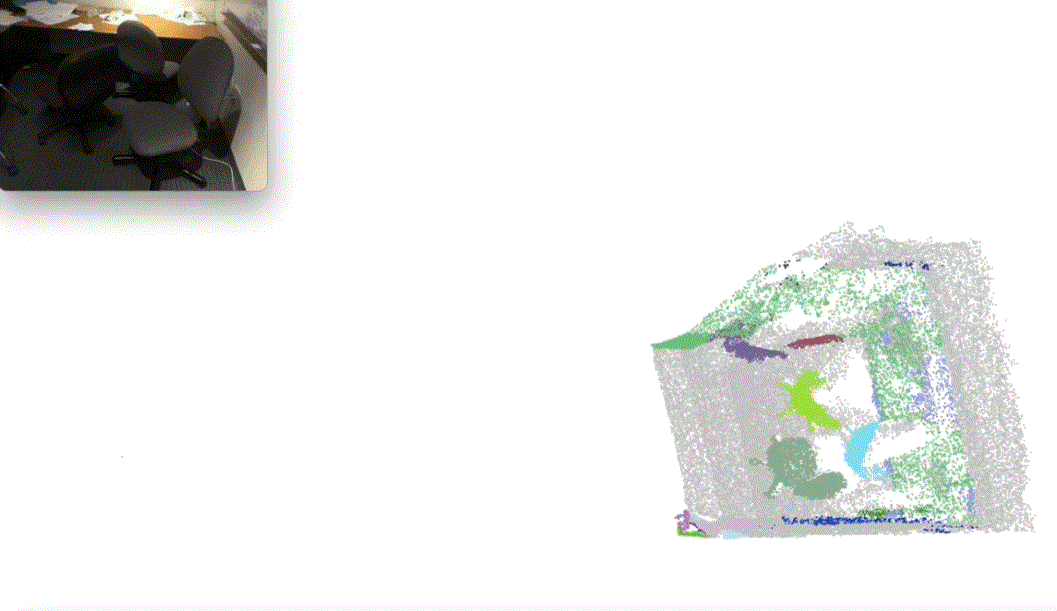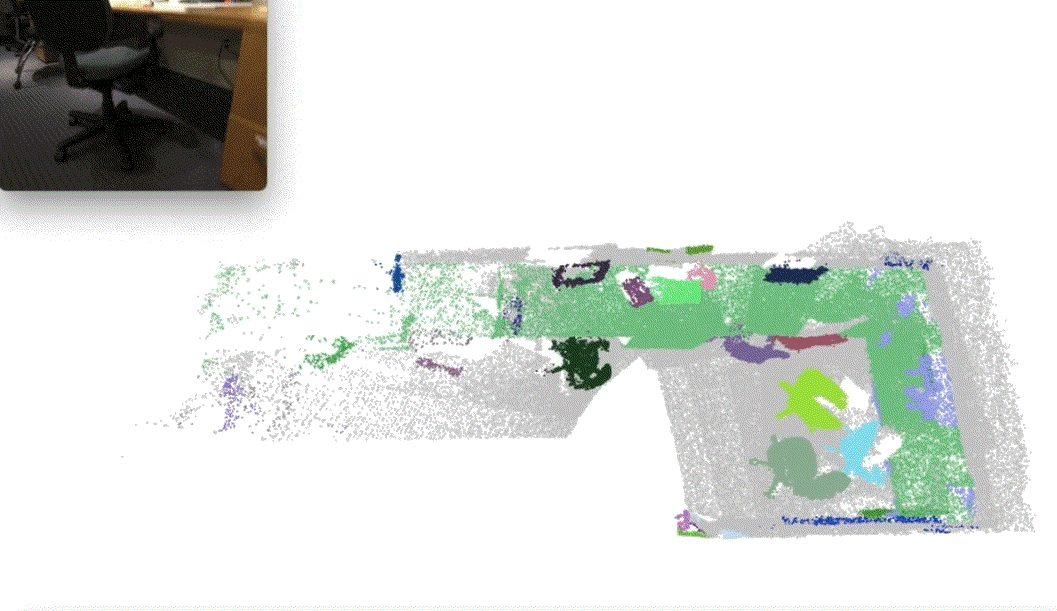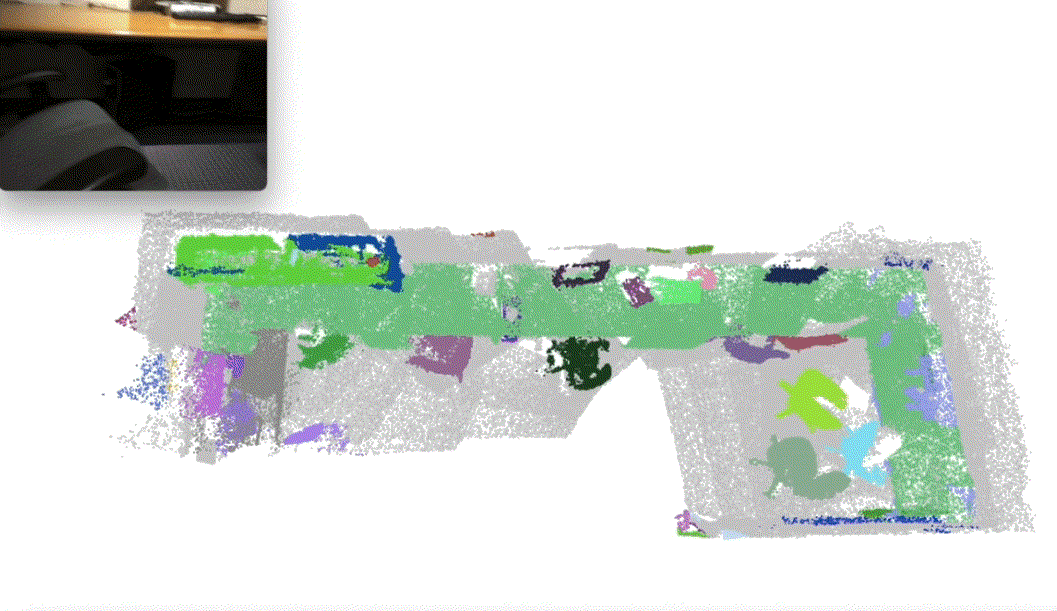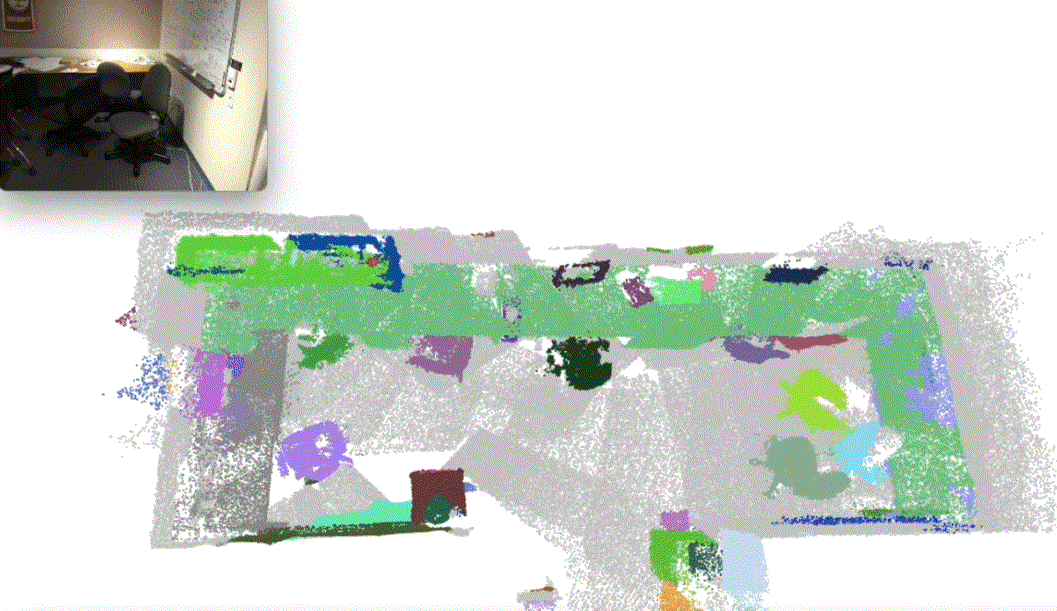
Xiuwei Xu, Huangxing Chen, Linqing Zhao, Ziwei Wang, Jie Zhou, Jiwen Lu International Conference on Learning Representations (ICLR), 2025 (Oral, Top 1.8% Submission) [arXiv] [Code] [Project Page] [中文解读] We presented ESAM, an efficient framework that leverages vision foundation models for online, real-time, fine-grained, generalized and open-vocabulary 3D instance segmentation. |
|
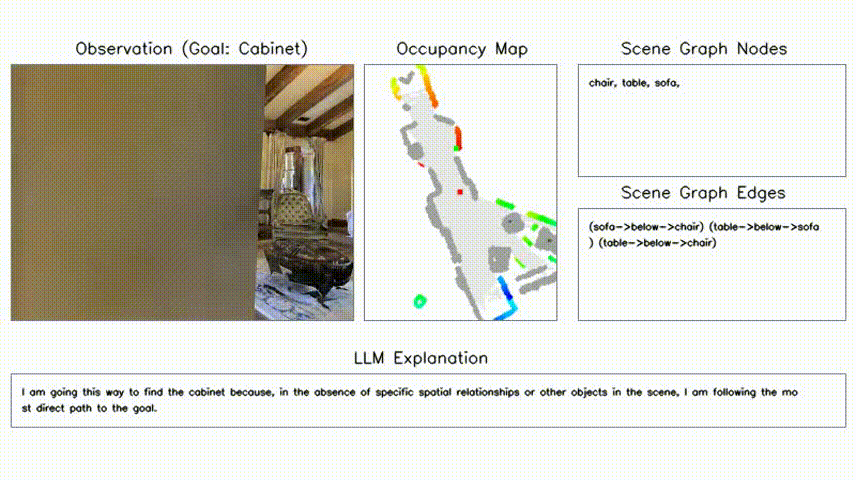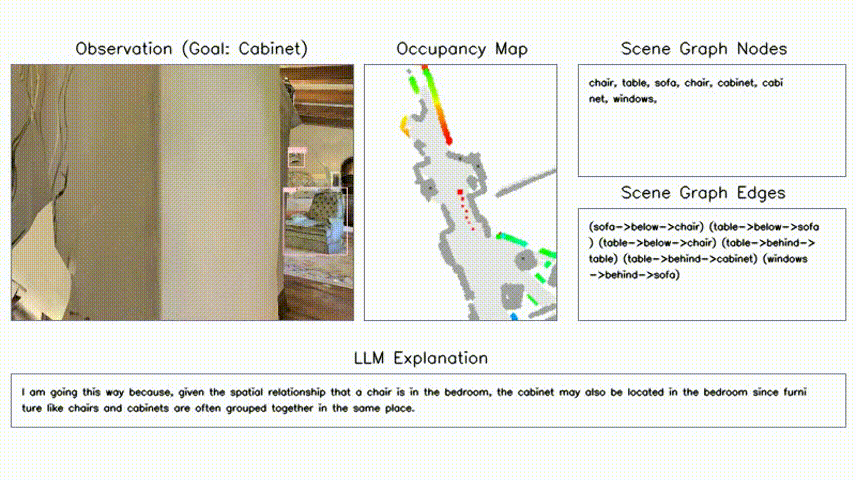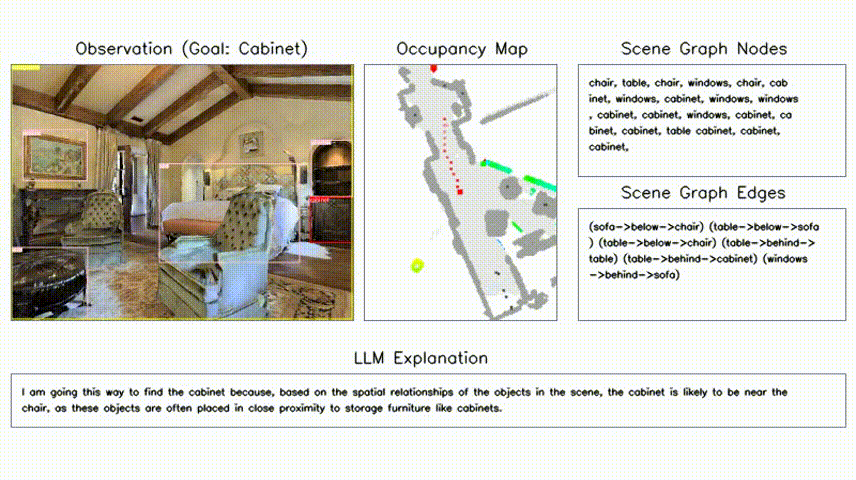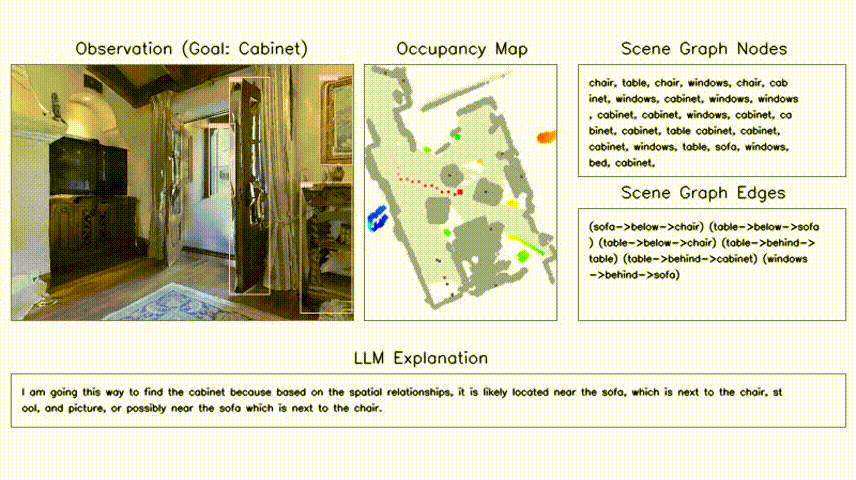
Hang Yin*, Xiuwei Xu*†, Zhenyu Wu, Jie Zhou, Jiwen Lu Neural Information Processing Systems (NeurIPS), 2024 [arXiv] [Code] [Project Page] [中文解读] We propose a training-free object-goal navigation framework by leveraging LLM and VFMs. We construct an online hierarchical 3D scene graph and prompt LLM to exploit structure information contained in subgraphs for zero-shot decision making. |
|
Xiuwei Xu*, Zhihao Sun*, Ziwei Wang, Hongmin Liu, Jie Zhou, Jiwen Lu European Conference on Computer Vision (ECCV), 2024 [arXiv] [Code] [Project Page] [中文解读] We propose an effective and efficient 3D detector named DSPDet3D for detecting small objects. By scaling up the spatial resolution of feature maps and pruning uninformative scene representaions, DSPDet3D is able to capture detailed local geometric information while keeping low memory footprint and latency. |
|
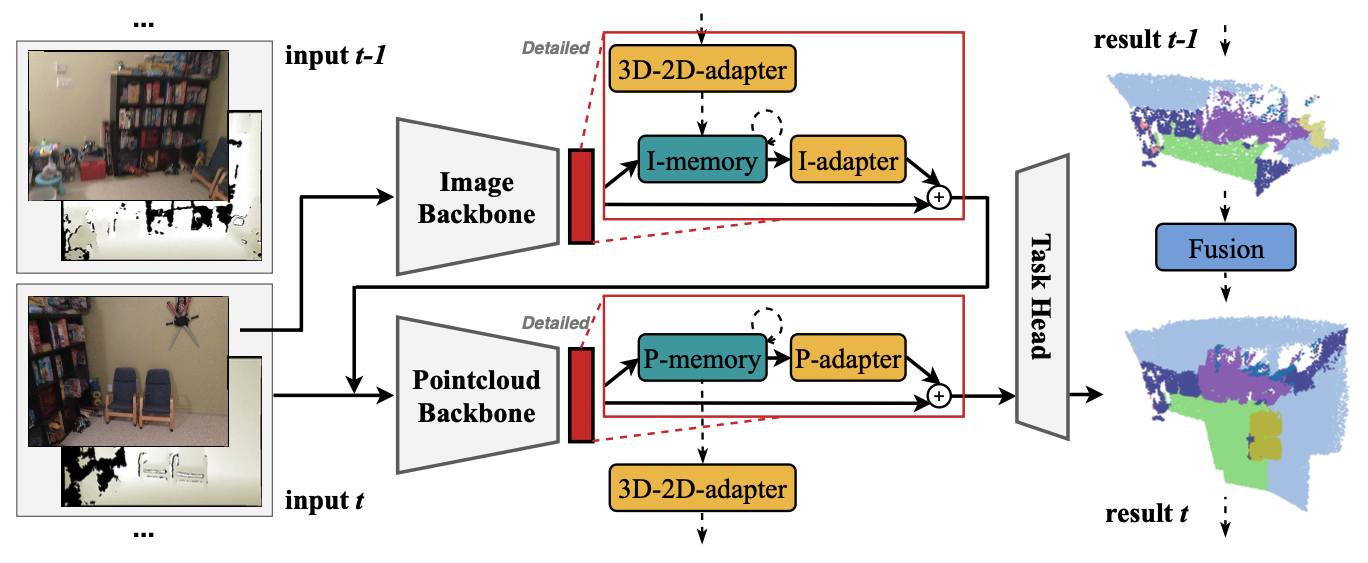
Xiuwei Xu*, Chong Xia*, Ziwei Wang, Linqing Zhao, Yueqi Duan, Jie Zhou, Jiwen Lu Computer Vision and Pattern Recognition (CVPR), 2024 [arXiv] [Code] [Project Page] [中文解读] We propose a model and task-agnostic plug-and-play module, which converts offline 3D scene perception models (receive reconstructed point clouds) to online perception models (receive streaming RGB-D videos). |
|
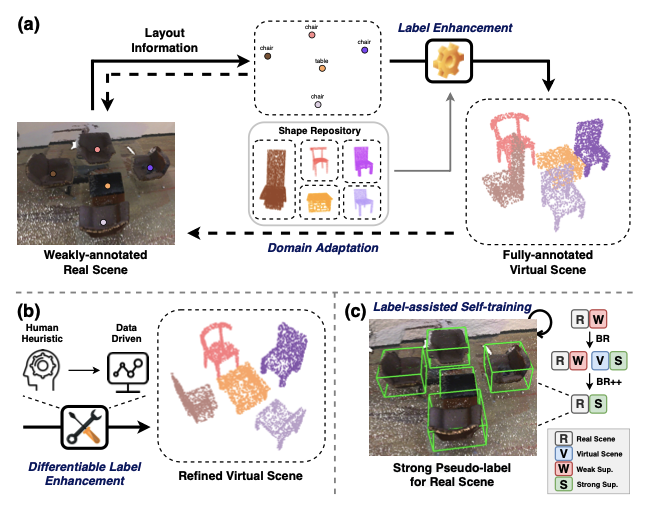
Xiuwei Xu, Yifan Wang, Yu Zheng, Yongming Rao, Jie Zhou, Jiwen Lu Computer Vision and Pattern Recognition (CVPR), 2022 IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI, IF: 23.6), 2023 [arXiv] [Code] [Poster] [PDF (Journal)] [Supp (Journal)] We propose a weakly-supervised approach for 3D object detection, which makes it possible to train a strong 3D detector with only annotations of object centers. We convert the weak annotations into virtual scenes with synthetic 3D shapes and apply domain adaptation to train a size-aware detector for real scenes. |
|
|
Data-efficient Mobile ManipulationIn this project, we study the challenging mobile manipulation task, which requires an accurate and proper combination of navigation and manipulation. Since whole-body mobile manipulation data is limited, we define this task as a subsequent stage of navigation. However, existing navigation methods end at a very coarse location which is usually 3-5m away from the manipulation area, which is far from the <5mm accuracy required by maniulation polices. Therefore, we propose: (1) optimization-based framework for docking point selection, serving as an intermediate stage of navigation and fixed-base manipulation and (2) 3D policy and 3D data generation to train generalized policy with minimal data, which enables robust manipulation under any viewpoint, object location and appearance. Our works are summarized as: |
3D Representation for Visual NavigationIn this project, we study how to design a proper representation and how to exploit the representation for general visual navigation. Previous methods mainly focus on BEV map or topological graph, which lacks 3D information to reason fine-grained spatial relationship and detailed color / texture. Therefore, we leverage 3D representation for better modeling of the observed 3D environment. We propose: (1) 3D scene graph as a structural representation for explicit LLM reasoning and unification of different kinds of tasks and (2) 3D gaussians as a renderable representation for accurate image-goal navigation. Our works are summarized as: |
Efficient and Online 3D Scene PerceptionIn this project, we study how to make 3D scene perception methods applicable for embodied scenarios such as robotic planning and interaction. Although various research have been conducted on 3D scene perception, it is still very challenging to (1) process large-scale 3D scenes with both high fine granularity and fast speed and (2) perceive the 3D scenes in an online and real-time manner that directly consumes streaming RGB-D video as input. We solve these problems in below works: |
|
|
|
|
|
|
|
|